文章內容

人工智慧的分級與歷史

請自行調高解析度
❐ 人工智慧的定義與範圍
人工智慧(AI:Artificial Intelligence)是指人類製造出來的機器所表現出來的智慧,人工智慧研究的範圍很廣,包括:演繹、推理和解決問題、知識表示法、規劃與學習、自然語言處理、機器感知、機器社交、創造力等,而我們常常聽到的「機器學習(Machine learning)」是屬於人工智慧的一部分,另外「深度學習(Deep learning)」又屬於機器學習的一部分,如<圖一>所示。
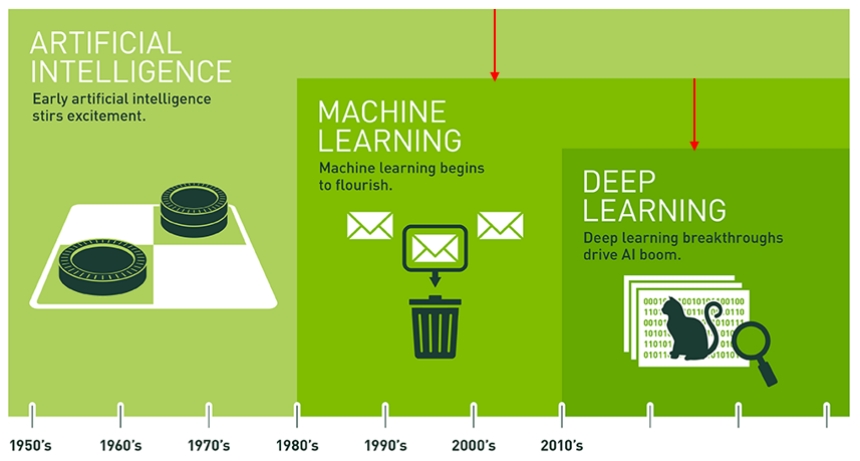
圖一 人工智慧、機器學習、深度學習的範圍。
參考資料:blogs.nvidia.com.tw。
❐ 人工智慧的分級
人工智慧的依照機器(電腦)能夠處理與判斷的能力區分為五個分級如下:
➤第一級人工智慧(First level AI):第一級人工智慧是指機器(電腦)含有自動控制的功能,可以經由感測器偵測外界的溫度、濕度、亮度、震動、距離、影像、聲音等訊號,經由控制程式自動做出相對的反應,例如:吸塵器、冷氣機等,這個其實只是電腦含有自動控制的程式,程式設計師必須先把所有可能的情況都考慮進去才能寫出控制程式,算不上是真的「智慧」。
第一級人工智慧就好像是公司裡的工讀生:只是執行老板交待的命令,進行各種重複性的工作,並不會去思考這個命令是否正確,例如:老板說把大箱子搬到寫有「大」的區域;小箱子搬到「小」區域,工讀生就依照老板的交待去做。
➤第二級人工智慧(Second level AI):是指機器(電腦)可以探索推論、運用知識,是基本典型的人工智慧,利用演算法將輸入與輸出資料產生關聯,可以產生極為大量的輸入與輸出資料的排列組合,可能的應用包括:拼圖解析程式、醫學診斷程式等。
第二級人工智慧就好像是公司裡的員工,能夠理解老板交待的規則並且做出判斷,例如:老板說根據箱子長、寬、高分類大小箱子,運用知識留意不同貨物種類:小心易碎、易燃物品,員工就依照這個意思把箱子的尺寸量出來分類,並且要判斷什麼貨物「易碎」或「易燃」?
➤第三級人工智慧(Third level AI):是指機器(電腦)可以根據資料學習如何將輸入與輸出資料產生關聯,「機器學習(Machine learning)」是指根據輸入的資料由機器自己學習規則,可能的應用包括: 搜尋引擎、大數據分析等。
第三級人工智慧就好像是公司裡的經理,能夠學習原則並且自行判斷,例如:老板給予大箱子與小箱子的判斷原則(特徵值),讓經理自己學習如何判斷多大是大箱子?經理就依照以往的經驗,自己思考多大的箱子是「大」?知識力www.ansforce.com。
➤第四級人工智慧(Fourth level AI):是指機器(電腦)可以自行學習並且理解機器學習時用以表示資料的「特徵值」,因此又稱為「特徵表達學習」 ,可能的應用包括: Google教會電腦貓的特徵。
第四級人工智慧就好像是公司裡的總經理,能夠發現規則並且做出判斷,例如:發現有一個箱子雖然很大但是卻是圓形(特徵值),與其他貨物不同應該另案處理。
第三級(主要是指機器學習)與第四級(主要是指深度學習)不容易區分,其實深度學習是由機器學習發展而來,主要的差別在於,第三級人工智慧處理資料時的「特徵值」必須由人類告訴機器(電腦);第四級人工智慧處理資料時的「特徵值」可以由機器(電腦)自己學習而得,這是人工智慧很大的突破,我們會在後面的文章詳細說明。知識力www.ansforce.com。
❐ 人工智慧的歷史
自從人類發明了第一台電腦,就開始了人工智慧相關的發展,到現在已經超過半個世紀,其間經歷過三次熱潮,之前每次都因為某些技術上的困難無法突破,我們先來介紹一下人工智慧發展的歷史,以及每一次熱潮興起的原因與遭遇的困難。
➤第一次熱潮(1950~1960):由1950年代開始發展「程式的搜尋與推論」,主要是利用電腦針對特定問題進行搜尋與推論並且予以解決,但是當時的電腦計算能力有限,一遇到複雜的問題就束手無策,被戲稱為只能解決玩具問題的人工智慧,因此到了1960年代就冷卻了下來。
➤第二次熱潮(1980~1990):由1980年代開始發展「知識的輸入與判斷」,主要是把大量專家的知識輸入電腦中,電腦依照使用者的問題判斷答案,專家系統應用在疾病診斷,連續的問題有一個判斷錯誤則得到錯誤的結果,而且知識是無窮無盡的,不可能把所有的知識都輸入電腦,還把所有知識的前後順序都找出來,因此最後變得不實用,到了1990年代又冷卻了下來。
➤第三次熱潮(2000~現在):由2000年代開始發展「機器學習與深度學習」,由於半導體技術的進步提升了很大的運算能力,而且半導體成本的下降使用雲端儲存變得便宜,在雲端伺服器內收集了世界各地的「大數據(Big data)」,為人工智慧建立了很好的發展基礎,其中機器學習(Machine learning)是經由大數據來訓練電腦「學習」資料的特徵值;深度學習(Deep learning)是經由大數據來訓練電腦自行「理解」資料的「特徵值」,又稱為「特徵表達學習」。
由於半導體技術的進步與成本的下降,使得大量的數據的儲存與運算變得容易,提供了人工智慧極佳的發展環境,依照目前整個科技產業的發展,我們不必擔心這一次的人工智慧會有冷卻的一天,相反的,我們該擔心人工智慧的過度發展,會不會有一天對我們造成負面的影響。
❐ 人工智慧的雲端與終端
網際網路(Internet)是一個開放的空間,由數以億計的電腦主機與伺服器連結而成,如<圖二(a)>所示,要如何描述這麼多電腦主機與伺服器架構而成的系統呢?因此科學家們使用「雲端(Cloud side)」這樣的名詞來代表這個系統,相對於使用者所在的「終端(Edge side) 」,如<圖二(b)>所示。
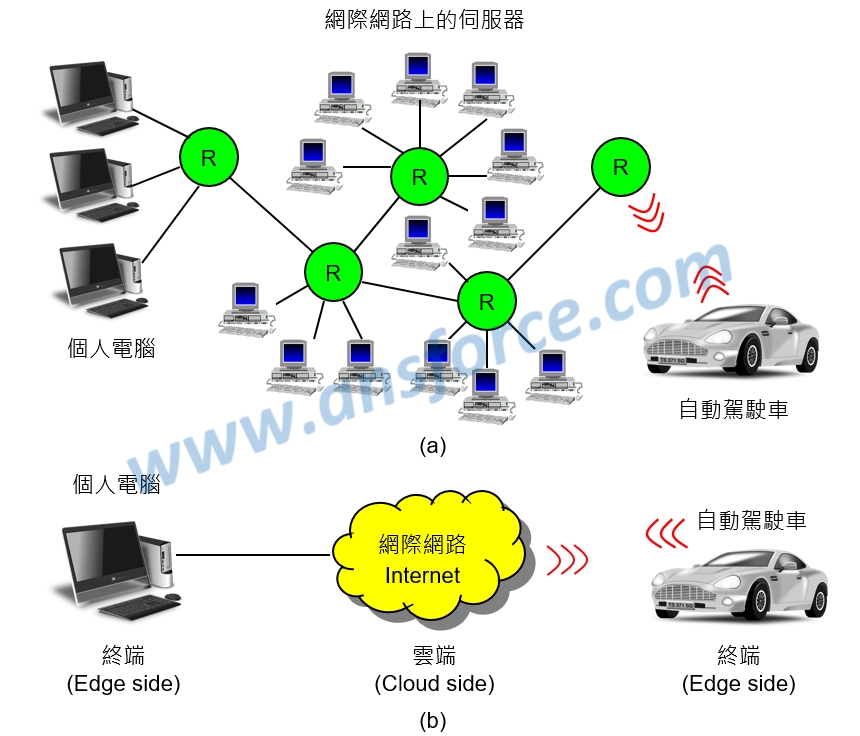
圖二 人工智慧的雲端與終端示意圖。
人工智慧(AI)大量的學習與運算目前都借助於雲端伺服器強大的處理器來進行,早期使用Intel的「中央處理器(CPU:Central Processing Unit)」,後來科學家發現Nvidia的「圖形處理器(GPU:Graphics Processing Unit)」效能比CPU高100倍以上,Intel經由併購Altera取得「可程式化邏輯陣列(FPGA:Field Programmable Gate Array)」技術來與GPU抗衡,另外有更多的廠商開發始發展「特定應用積體電路(ASIC:Application Specific Integrated Circuit)」,例如:Google自行設計的「張量處理器(TPU:Tensor Processing Unit)」或Intel自行設計的「視覺處理器(VPU:Vision Processing Unit)」,就是一種針對人工智慧這種「特定應用」所開發的積體電路,以上這些處理器都是裝置在「雲端(Cloud side)」。然而並不是所有的應用都適合把大數據傳送到雲端處理,例如:自動駕駛車必須在車上「終端(Edge side)」進行處理才能即時反應道路情況。
蘋果公司這次推出的iPhone X使用自行開發的A11處理器,內建雙核心的「神經網路引擎(NE:Neural Engine)」,專門處理圖像辨識相關的機器學習、推論模型、演算法,也是一種針對人工智慧這種「特定應用」所開發的積體電路,不同的是它裝置在「終端(Edge side)」,也就是使用者的手機上,讓手機可以「自動學習」認識使用者的臉部特徵,蘋果公司也一再強調,使用者所有的臉部特徵都在手機終端完成,不會上傳到雲端處理,因此絕對不會有資料外洩的疑慮。蘋果公司這次發表的iPhone X讓使用者能夠真實感受終端裝置的人工智慧(On-device AI),在可以預見的未來,終端的處理器如何與人工智慧結合形成「終端智能(Edge intelligence)」, 將是愈來愈熱門的議題。
【請注意】上述內容經過適當簡化以適合大眾閱讀,與產業現狀可能會有差異,若您是這個領域的專家想要提供意見,請自行聯絡作者;若有產業與技術問題請參與社群討論。
【參考資料】松尾豐、江裕真,了解人工智慧的第一本書,經濟新潮社。<我要買書>