文章內容

人工神經網路(ANN:Artificial Neural Network)

請自行調高解析度
❐ 神經網路(NN:Neural Network)
人類大腦的神經網路是由「神經元(Neural)」組成,大腦中大約有860億個神經元,神經元是用來感知環境的變化,再將信息傳遞給其他的神經元,基本構造包括:細胞體(內含細胞核)、樹突(Dendrites)、軸突(Axon)組成,如<圖一(a)>所示:
➤突觸(Synapse):神經元與神經元、肌肉細胞、腺體細胞之間通信的特異性接頭(Junction),用來傳遞生物電流或化學物質(多巴胺、乙醯膽鹼)。
➤接收區(Receptive zone):為樹突到胞體的部份,用來接收生物電流或化學物質,如果接收的來源越多,對胞體電位的影響越大。
➤觸發區(Trigger zone):位於軸突和細胞體交接處的「軸丘(Axon hillock)」,用來決定是否產生神經衝動的起始點。知識力www.ansforce.com。
➤傳導區(Conducting zone):為軸突的部份,用來傳導神經衝動。
➤輸出區(Output zone):神經衝動的目的是讓神經末梢,也就是突觸傳遞生物電流或化學物質,才能影響下一個神經元、肌肉細胞、腺體細胞。
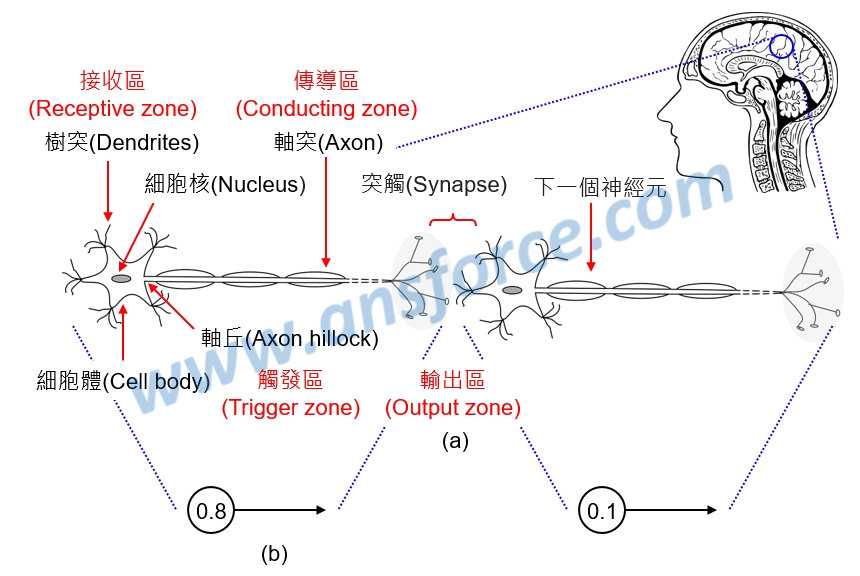
圖一 人類大腦的神經網路(NN)示意圖。
❐ 人工神經網路(ANN:Artificial Neural Network)
人工神經網路(ANN)又稱為「類神經網路」,是一種模仿生物神經網路的結構和功能所產生的數學模型,用於對函式進行評估或近似運算,是目前人工智慧最常使用的一種「模型(Model)」。科學家模仿人類大腦的神經網路,提出了「赫布理論(Hebbian theory)」,用來解釋學習過程中大腦神經元變化的神經科學理論,突觸上一個神經元向突觸下一個神經元持續重複的刺激,可以導致突觸傳遞效能增加,也就是人工神經網路上的「權重(Weight)」。知識力www.ansforce.com。
我們把人類大腦複雜的「神經元(Neural)」簡化成一個圓圈和一個箭號,如<圖一(b)>所示,圓圈內的數字代表這個神經元的神經衝動強度,箭號旁的數字代表這個神經元突觸傳遞效能,也就是「權重(Weight)」,則大腦內複雜的神經網路就可以簡化成人工神經網路,如<圖二>所示,一層層的連結起來,以手寫辨識數字為例,「輸入層」就是我們手寫的數字,「輸出層」就是辨識的結果數字0~9。
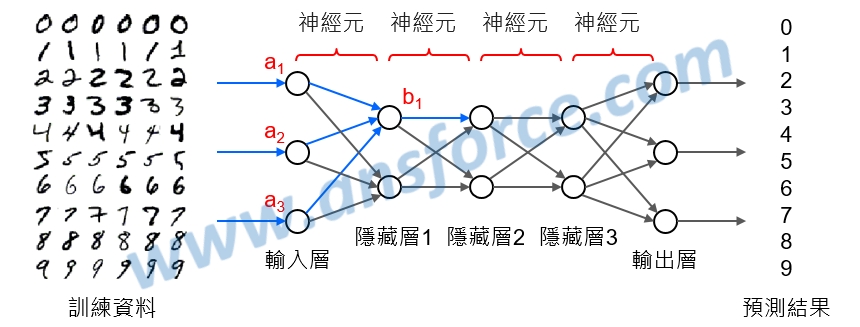
圖二 人工神經網路(ANN)示意圖。
❐ 單層感知器(SLP:Single Layer Perceptron)
1958年Frank Rosenblatt發明「感知器(Perceptron)」,經由赫布理論最小化單層網路的權重,是第一個以演算法精確定義的神經網絡,也是第一個具有自我學習能力的數學模型,為後續人工神經網路模型的始祖,神經網路模型的運算原理很簡單,這一個神經元由前一個神經元接收到的電氣訊號達到某一個「門檻值(Threshold point)」就會產生神經衝動,同時把電氣訊號傳送給下一個神經元,運算步驟如下:
➤乘加運算(SOP:Sun of Product):下一個神經元(b1)接收到的訊號強度是由這一層神經元(a1/a2/a3)進行加權(w1/w2/w3)之後的總和(Sun),如<圖三(a)>所示。
➤激勵函數(Activation function):感知器使用激勵函數的目的是引入非線性,如<圖三(b)>所示,常見的激勵函數有邏輯函數(Sigmoid function)、雙曲函數(tanh)、線性整流函數(ReLU:Rectified Linear Unit)等,在人工神經網路中如果不使用激勵函數,那麼都是以上一層神經元輸入的線性組合作為這一個神經元的輸出,輸出和輸入脫離不了線性關係,則深度神經網路便失去意義。
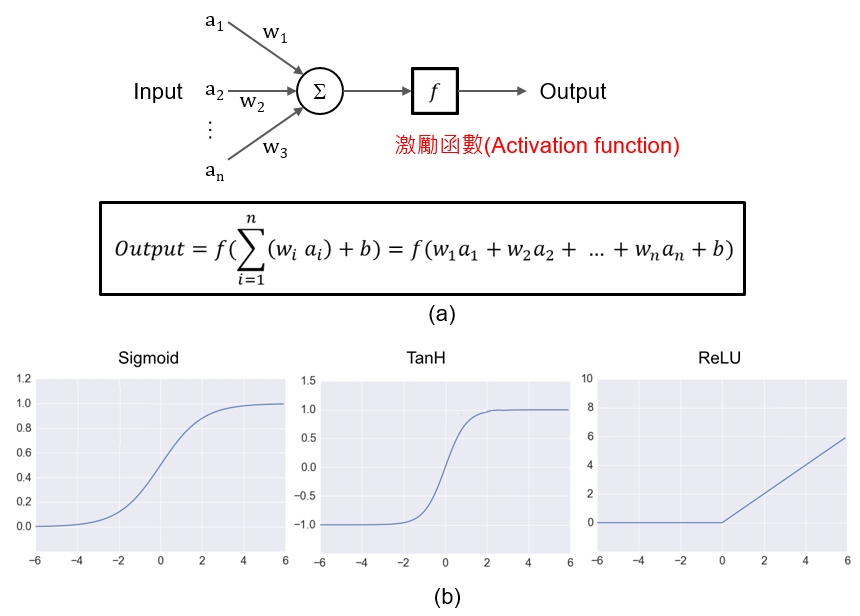
圖三 單層感知器(SLP)與激勵函數示意圖。
❐ 神經網路模型(Neural network model)
人類大腦的神經元會因為反覆學習而使得突觸間傳遞作用加強,就好像這裡的人工神經網路權重變大,因此這種分類法是參考人類大腦神經網路的原理。神經網路模型的運算如<圖四(a)>所示,假設這一層神經元(a1/a2/a3)連結到下一個神經元(b1),分別為權重(w1/w2/w3),則下一個神經元(b1)的神經衝動強度經由感知器(Perceptron)的乘加運算(SOP)為:
b1=w1×a1+w2×a2+w3×a3=0.5×0.8+2.5×0.2+(−2.9)×1.0=−2.0
如<圖四(b)>所示,再將-2.0經由「邏輯函數(Sigmoid function)」轉換後得到輸出值0.1,如<圖四(c)>所示。知識力www.ansforce.com。
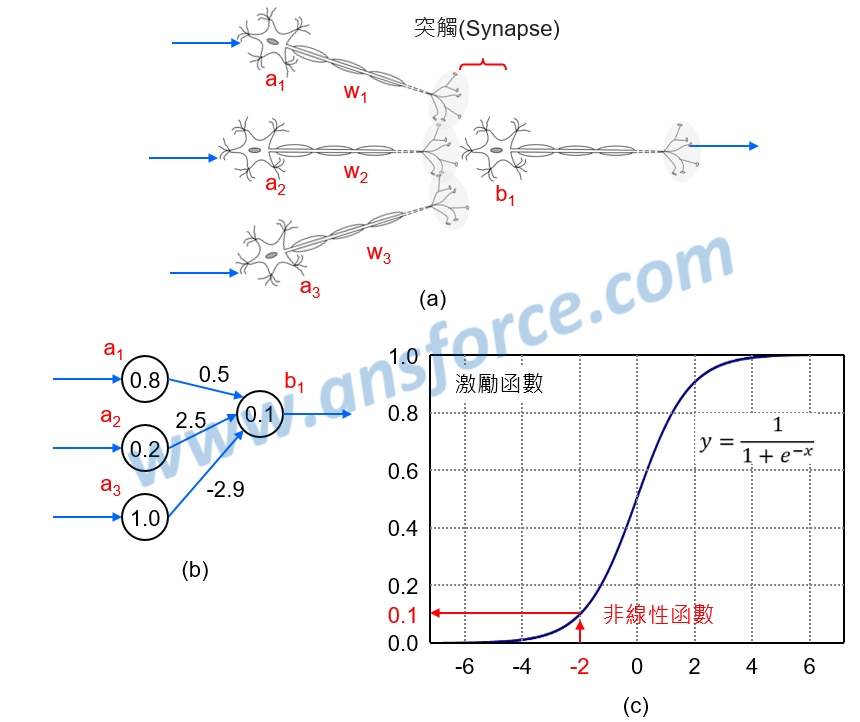
圖四 神經網路模型的運算示意圖。
❐ 經由人工神經網路(ANN)訓練電腦進行手寫辨識
在圖形辨識領域的科學家們必須共同使用一套標準圖形資料庫,才能確定是開發出更好的演算法,而不是運氣好恰好資料比較好解讀,因此許多科學家使用「MNIST資料庫(Modified National Institute of Standards and Technology)」,以手寫辨識為例,在MNIST資料庫中的每個數字都是28×28=784畫素(Pixel)的灰階圖片,每一個畫素可以轉換成一個0~255的數字,其中0代表黑色,1代表有一點亮的灰色,2代表更亮的灰色,依此類推,255代表白色,如<圖五>所示。總共有七萬張圖片,每一個手寫數字圖片都有標準答案對應到正確的數字,因此是屬於「監督式學習(Supervised learning)」。
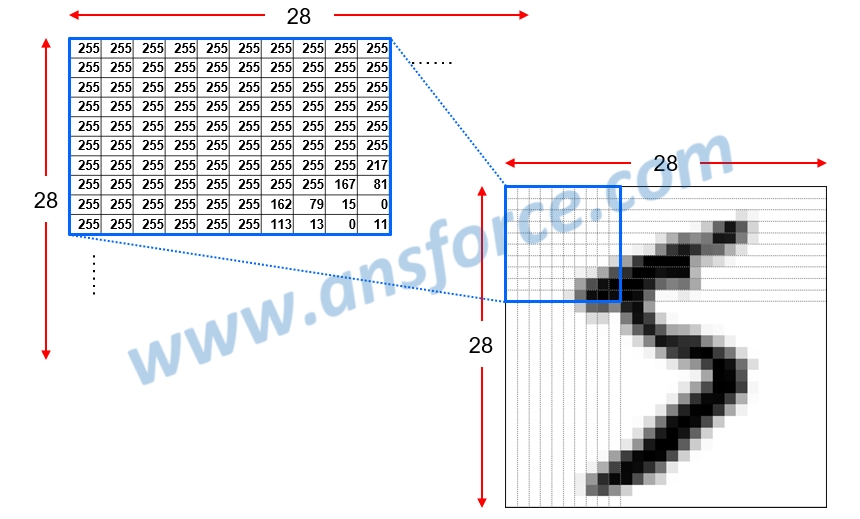
圖五 MNIST資料庫中的每個數字都是28×28=784畫素的灰階圖片。
由於每個數字都是28×28=784畫素,每一個畫素的數字就是輸入層的1個維度,因此輸入層總共784個維度,假設我們設定隱藏層有100個維度,輸出層只有數字0~9總共10個維度,如<圖六>所示:
➤輸入層(Input layer):每個數字有784畫素,總共784個維度(a1~a784)輸入。
➤隱藏層(Hidden layer):假設我們設定隱藏層有100個維度(b1~b100)。
➤輸出層(Output layer):只有數字0~9總共10個維度(c1~c10)輸出。
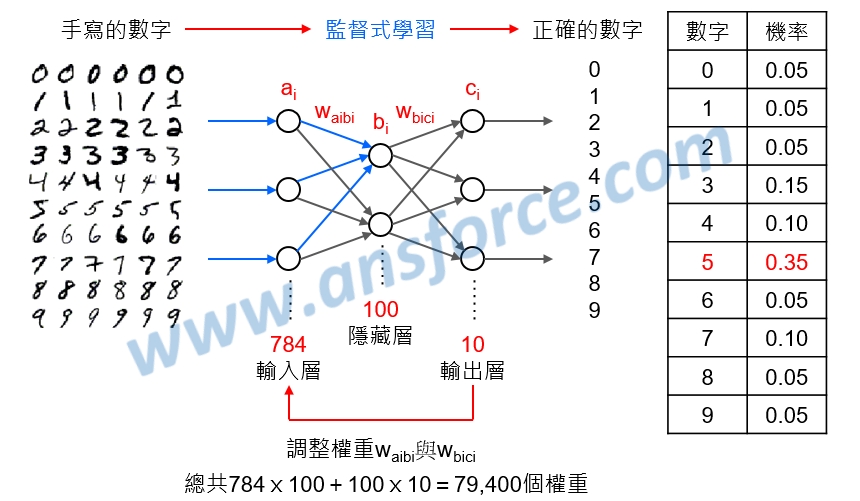
圖六 手寫辨識的人工神經網路運算示意圖。
除了每一層的維度,我們還要注意每一層之間的「權重(Weight)」,在這個例子裡總共有784×100+100×10=79,400個權重,我們來計算一下隱藏層的100個維度(b1~b100):
b1=w(a1b1)×a1+w(a2b1)×a2+w(a3b1)×a3+……+w(a784b1)xa784
b2=w(a1b2)×a1+w(a2b2)×a2+w(a3b2)×a3+……+w(a784b2)xa784
依此類推
b100=w(a1b100)×a1+w(a2b100)×a2+w(a3b100)×a3+……+w(a784b100)xa784
再計算一下輸出層的10個維度(c1~c10):
c1=w(b1c1)×b1+w(b2c1)×b2+w(b3c1)×b3+……+w(b100c1)×b100
c2=w(b1c2)×b1+w(b2c2)×b2+w(b3c2)×b3+……+w(b100c2)×b100
依此類推
c10=w(b1c10)×b1+w(b2c10)×b2+w(b3c10)×b3+……+w(b100c10)×b100
❐ 誤差反向傳播(EBP:Error Back Propagation)
人類的神經元會因為反覆學習而使得突觸間傳遞作用加強,就好像這裡的人工神經網路權重變大,因此這種分類法是參考人類大腦神經網路的原理。經由微分計算每一個權重變大或變小時,輸出層與輸入層的誤差會變小,經由不停反覆調整79,400個權重,也就是所有的w(aibi)與w(bici),使得輸出層與輸入層的誤差變小,在<圖六>這個例子裡,輸入手寫的數字「5」,因此必須不停反覆調整79,400個權重使得輸出正確的數字「5」的機率(0.35)最高。這個觀念類似主管經由員工提供的資訊進行判斷,正確的資訊是由下(員工)向上(主管)提供(反向傳播),而修正時由上(主管)向下(員工),慢慢就會判斷正確。
❐ 神經網路的訓練與預測
我相信大家看到這裡頭就開始昏了~事情還沒結束,神經網路的學習與預測流程比前面講的還要複雜:
➤訓練階段:輸入大量已知答案的資料進行訓練,當輸出結果出現錯誤就調整79,400個權重,反覆進行直到輸出的結果接近標準答案,可能需要幾秒也可能需要幾天。例如:輸入七萬張手寫數字圖片都有標準答案對應到正確的數字,每當任何一張圖片輸出結果出現錯誤就調整79,400個權重,也就是w(aibi)與w(bici),直到輸出與輸入的誤差最小。
➤推論階段:輸入不同於訓練階段的新資料,經由已經調整好的79,400個權重計算後輸出結果,就是這個人工神經網路預測的結果,只需要一瞬間就可以完成,精確度有賴於訓練時得到的權重。
由上面的例子可以看出,神經網路的訓練與預測和人類的學習與判斷過程相似,我們通常都是花很長的時間學習(訓練),但是學會之後進行判斷(預測)只需要一瞬間就可以了。
❐ 機器學習的模型(Model)
資料科學是一種收集資料、了解資料、分析資枓、預測資料的科學,資料裡不同變數之間存在數學上或機率上的規則稱為「模型(Model)」,可以應用在許多地方,例如:圍棋比賽可以運用某種模型分析出過的牌、出現的牌來評估每個玩家的勝率,模型必須基於圍棋規則、機率理論、基本假設等來建立。
機器學習就是經由資料分析建立模型,並且使用這個模型來預測結果。有人把這種技術稱為「資料探勘(Data mining)」或「預測建模(Predictive modeling)」,例如:預測某封電子郵件是否為垃圾郵件、預測某筆線上交易是否為詐欺行為等。知識力www.ansforce.com。
為了建立模型必須選擇相關的「特徵值(Feature value)」,我們稱為「特徵選擇(Feature selection)」,特徵值是機器學習在輸入時所使用的「變數(Valuable)」,它的數值可以定量呈現目標的特徵,隨著挑選特徵值的不同會讓精確度產生很大的影響。例如:手寫辨識必須調整手寫文字的中心與大小,並不是把手寫文字切割成許多畫素再輸入人工神經網路就可以得到精確的結果。
【請注意】上述內容經過適當簡化以適合大眾閱讀,與產業現狀可能會有差異,若您是這個領域的專家想要提供意見,請自行聯絡作者;若有產業與技術問題請參與社群討論。