文章內容

深度學習(DL:Deep Learning)


❐ 人工智慧的困難
機器學習有許多方法可以進行資料分類,近年來最流行也被證明最成功的方法就是「人工神經網路(ANN:Artificial Neural Network)」,經由前面的介紹,我們知道人工神經網路是如何調整權重,使輸出與輸入的誤差變小,但是即使如此,這和我們想要的「人工智慧」,也就是人工創造出來可以思考的電腦還有很大的差距,直到今日人工智慧無法實現的主要原因包括:
➤專家系統:輸入知識讓電腦變聰明,但是沒有自行學習的機制,必須先請專家提供所有知識,而且知識無窮無盡永遠也寫不完,知識數量太多彼此產生矛盾,無法處理不明確的答案。
➤框架問題:只能解決給定的問題,也就是問題必須在一定的「框架」內,對於不同的任務無法事先決定該使用什麼知識。知識力www.ansforce.com。
➤符號接地問題:無法把符號(文字或詞彙)與它所代表的意義相互連結起來,也就是電腦很難理解我們所謂的「意義」,因此無法產生「智慧」。
➤心物問題:我思(思想)故我在(主體),目前的技術還無法讓電腦有心(思想或精神)。
➤機器學習:利用人工神經網路(ANN)與誤差反向傳播(EBP:Error Back Propagation)來訓練電腦學習,但是必須由人類決定特徵值,電腦才能依照這個特徵值來訓練。
❐ 符號與意義
如果電腦可以自行分析資料找出特徵值,那就更接近我們想要的人工智慧,也就是人工創造出來可以思考的電腦。這個時候電腦能夠自己分析資料理解「有斑紋的馬」這個特徵,只要人類告訴電腦這個特徵所使用的符號叫「斑馬」,就把符號與它所代表的意義相互連結(接地)了!
符號「貓」或「Cat」,意義是指尖耳朵、尖眼睛、長鬍子很可愛的一種動物,這些就是「特徵值」,如<圖一>所示。人工智慧面臨許多問題就是因為電腦無法自行理解符號的「意義」,而最近發展的「深度學習」已經可以讓電腦自行分析資料找出「特徵值」。

圖一 符號「貓」與「特徵值」示意圖。
❐ 深度學習(Deep learning)
深度學習(深度神經網路)是讓電腦可以自行分析資料找出「特徵值」,而不是由人類來決定特徵值,就好像電腦可以有「深度」的「學習」一樣。而深度學習使用多層神經網路,理論上隱藏層愈多自由度與精確度愈高,但是結果相反,因為誤差反向傳播(EBP)很難傳遞回更上一層的神經元,就好像主管經由員工提供的資訊進行判斷,正確的資訊是由下(員工)向上(主管)提供(反向傳播),而修正時由上(主管)向下(員工),當階層太多時效果不佳。因此深度學習不但使用多層神經網路,同時使用「自動編碼器(Autoencoder)」來進行「非監督式學習(Un-supervised learning)」。
❐ 資料的縮減
深度學習的輸入層為手寫的數字,輸出層還是手寫的數字,會造成「權重(Weight)」增加,如<圖二>所示,我們簡單說明概念:
➤監督式學習:輸入層每個數字有784個維度,假設我們設定隱藏層有100個維度,輸出層只有數字0~9總共10個維度,在這個例子裡總共有784×100+100×10=79,400個權重,如<圖二(a)>所示。
➤非監督式學習:輸入層每個數字有784個維度,假設我們設定隱藏層有100個維度,輸出層每個數字也有784個維度,在這個例子裡總共有784×100+100×784=156,800個權重,如<圖二(b)>所示。
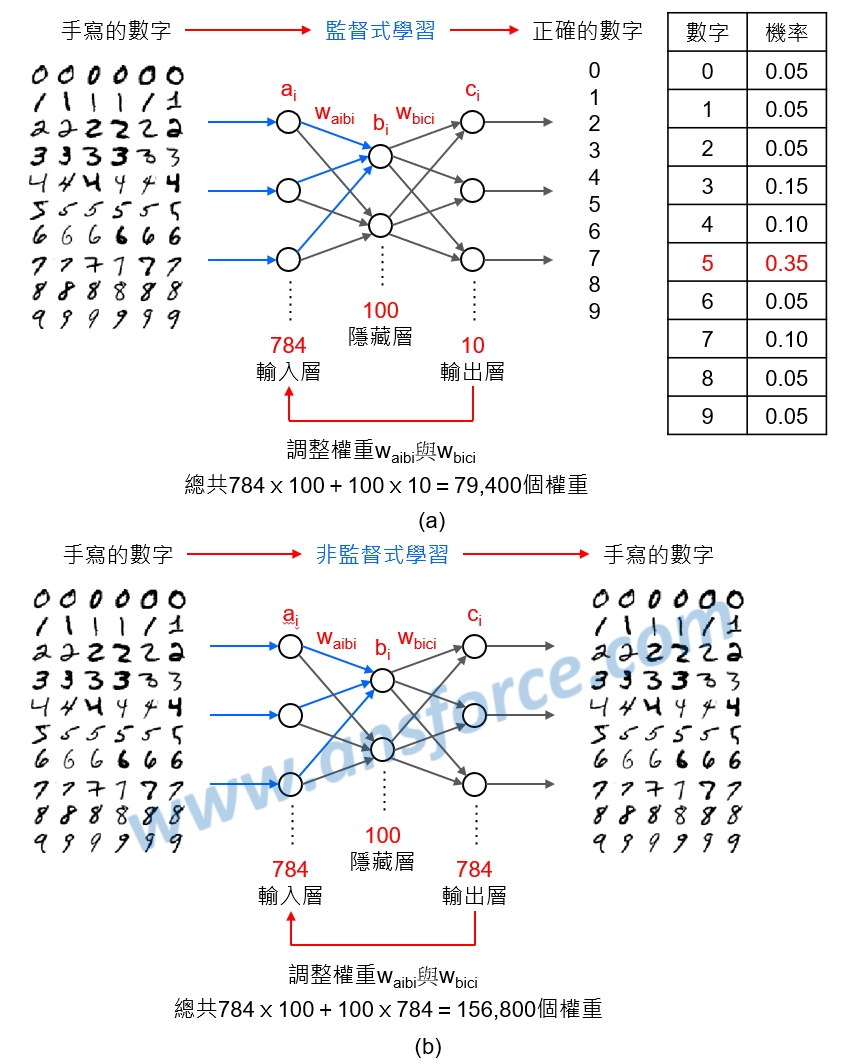
圖二 監督式學習與非監督式學習示意圖。
經由微分計算每一個權重變大或變小時,輸出層與輸入層的誤差會變小,經由不停反覆調整156,800個權重,也就是所有的w(aibi)與w(bici),使得輸出層與輸入層的誤差變小。這還是只有一個隱藏層所需要計算的權重,所謂的「深度」學習,就代表學習要有「深度」,意思是隱藏層不會只有一層,如<圖三(a)>所示,假設第一層隱藏層有100個維度、第二層隱藏層有80個維度、依此類推、第九層隱藏層有80個維度、第十層隱藏層有100個維度,那麼總共會有多少個權重呢?這些權重調整起來需要多少處理器的運算資源呢?現在明白為什麼人工智慧的「訓練(Training)」非常花時間了吧!
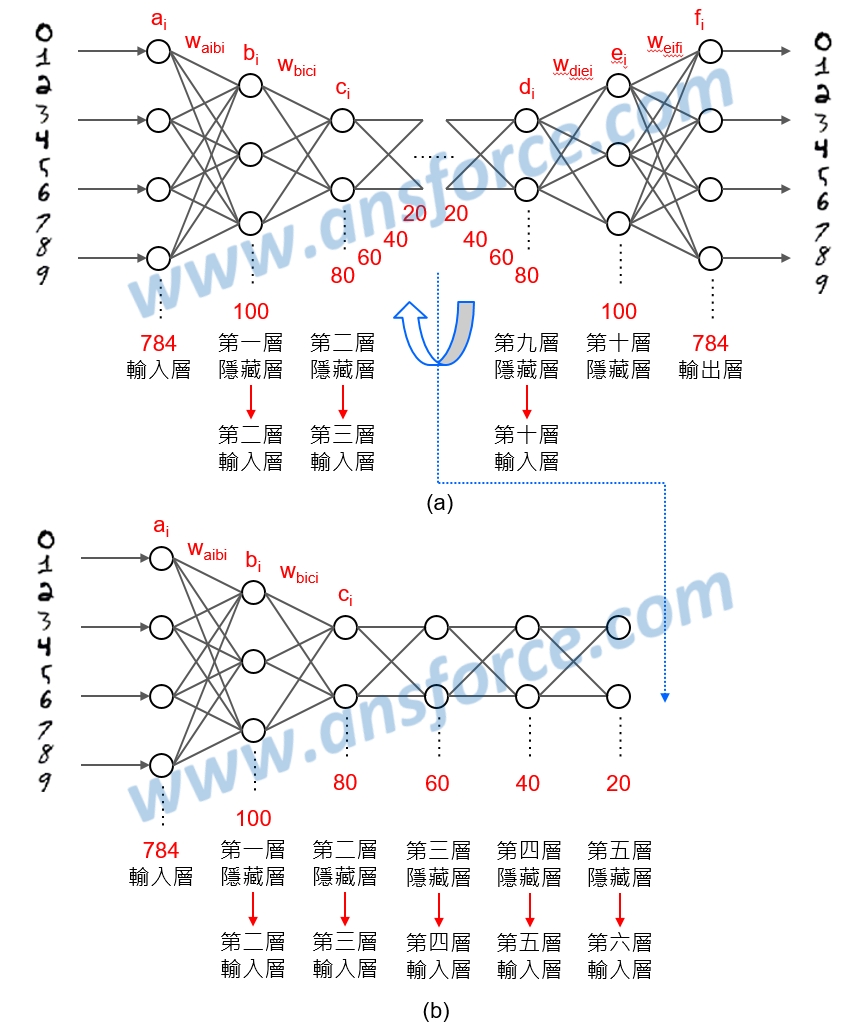
圖三 具有10層隱藏層的深度學習神經網路示意圖。
這麼多的權重調整起來極為費時,因此如何進行資料的縮減就變成重要的課題,如果是手寫辨識圖形相關的人工智慧運算,可以使用下列的方式:
➤當某個畫素為黑色,它相鄰的畫素是黑色的機率很高,因此可以把幾個畫素都視為黑色來處理,類似靜態影像壓縮技術(JPEG)的原理。
➤要把那幾個畫素都視為黑色來處理,輸出層與輸入層的圖形接近(誤差變小),電腦必須嘗試把不同的畫素都視為黑色來處理,自行學習找出「特徵值」。
➤當電腦學習到將右上角某一個畫素相鄰的10個畫素都視為黑色來處理,輸出層與輸入層的圖形接近(誤差變小),則在隱藏層裡所有的權重就代表了特徵。
大家觀察<圖三(a)>會發現,輸入層有784個維度,隱藏層依次有100、80、60、40、20個維度,再依次有20、40、60、80、100個維度,輸出層又回到784個維度,而且輸出層與輸入層的圖形還要接近(誤差很小),那代表什麼意思?代表圖片輸入後,隱藏層的維度不論如何變少,最後輸出都能夠還原成輸入的樣子,那不就意謂著隱藏層裡保留下來的就是這個圖片最具有代表性的「特徵」嗎?不然怎麼可能用20個維度還原成784個維度還能夠還原成輸入的樣子?而且隱藏層愈多層代表深度愈深,取出來的「特徵」就更具有代表性了!這樣講是不是大家對「深度」學習更有感覺了呢?
反應快的人可能已經發現,如果非監督式學習的輸入層與輸出層都是手寫的數字,具有相同的維度,則<圖三(a)>是左右對稱的,如果我們把它以中線(藍色虛線)為準由右向左對折,得到如<圖三(b)>所示,這就是我們常常看到的深度學習示意圖了!知識力www.ansforce.com。
❐ Google貓臉辨識計畫
Google公司2012年做了一個實驗,由Youtube的影片中取出1000萬張圖片,使用具有100億個神經元的深度學習神經網路,由1000台電腦(16000個處理器),運算三天才完成。
➤將1000萬張圖片輸入深度學習神經網路,經由數層神經網路使電腦自行學習找出「特徵值」而能夠辨識「對角斜線」,如<圖四(a)>所示。
➤再經由數層神經網路使電腦能夠辨識「人臉」,如<圖四(b)>所示,以及「貓臉」,如<圖四(c)>所示,形成抽象度愈高的「特徵值」,最後經由特徵值理解這個東西的「意義」。
➤此時只要我們告訴電腦具有<圖四(b)>這個特徵值的東西稱為「人(符號)」;具有<圖四(c)>這個特徵值的東西稱為「貓(符號)」,電腦就能夠將符號與意義產生連結(接地)了!
➤未來只要我們輸入其他照片,電腦就能夠自動判斷這個是人,那個是猫,這個學習的過程其實和人類學習過程是類似的。知識力www.ansforce.com。
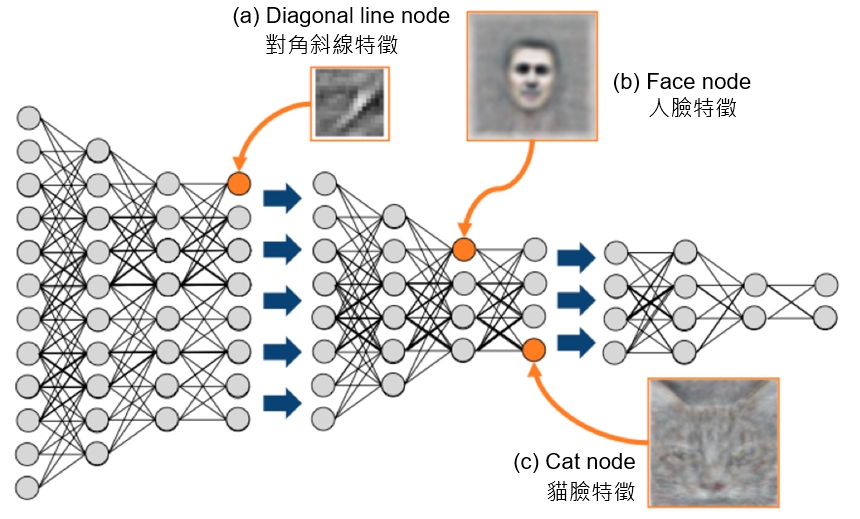
圖四 Google貓臉辨識計畫深度學習神經網路示意圖。
【請注意】上述內容經過適當簡化以適合大眾閱讀,與產業現狀可能會有差異,若您是這個領域的專家想要提供意見,請自行聯絡作者;若有產業與技術問題請參與社群討論。